
When working with eDiscovery projects, eventually you will end up having to handle a “load file” that will be provided from opposing counsel, or from a third-party data request. Over the past year and a half, our team has had a lot of experiences related to importing data. So much in fact, that we have been able to put together a list that we wanted to share with you of things to consider with importing data.
Editor
Have an editor that really supports the data formats that you will be working with. Microsoft Excel works, but it can be cumbersome when working with DAT files and large data sets. Try a tool like EmEditor. It has a DAT format display feature that works wonders!
Validation
When you first are looking at the load files, and the accompanying data (Native, OCR, Images, etc)… you may want to:
- Start with the basic counts. Number of records in the load file (csv, dat and image file) and number of files in the Native, OCR, and Image Folders… Depending on the agreed to ESI Protocols / Meet and Confer instructions, the numbers may not match, but you need to make sure that you are able to qualify the data before loading.
- Where you have discrepancies, you may need to have to dig into the load files and determine how many items should be missing. For Example, maybe Native files are only being provided for specific file formats (i.e.: Excel, Audio and Video, etc.). If you were to open the file in EXCEL and Filter on the Native Link field, you would be able to confirm how many should have been provided, and how many were not.
- Check for duplicate Field Names. Although uncommon, we have had experiences where the load file does have some duplicate field names that are caught when we are reviewing the load file.
- Check for how tags are handled. Although uncommon that you would be sharing tags with other parties, it may still come up as you move data between systems for your own review. Thus, understanding how the Tags are displayed/formatted in the load file, and how you need to import them into the system is important. Our experience has been that we end up loading the Tags into a Custom Field, and then after import we run searches to find the records and apply the appropriate tags manually.
Custom / Additional Fields
Not every field that is part of the load file will be directly mapped to the eDiscovery platform’s internal fields. You will inevitably need to create an additional or custom field to put the data into. Some of the things to consider here include:
- The format of the field (text, date, numeric, paragraph).
- The size/length of the field values that you are going to store. You may want to consider looking at the content of the load file, and try to determine what the Maximum length of some of the fields have been. We have found that if we are working from a template of Custom Fields, that occasionally the data is going to be longer than what the template was designed for. So in doing this check for Maximum Length, it may help save some time and the need for doing an additional data overlay.
- Check to see if every field is required to be imported. In general, the answer to this is Yes, because the ESI Protocol / Meet and Confer instructions said how data was to be provided… but it never hurts to ask whether or not a field that may seem to be irrelevant or may exceed system data types or limits (thus causing some issues), can be excluded.
Date Formats
When you are doing your review of the import files, you may notice that some fields have different date formats represented in them. From the format – MM/DD/YYYY or DD/MM/YYYY or YYYY-MM-DD or DD-MMM-YYYY, etc.. You may need to work with the software (or the data) to get it loaded into the system in the correct format. This same format issue may come into play if you are using Custom Fields that are of a DATE / NUMERIC format vs. TEXT.
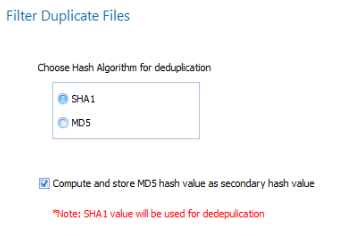
Hash Values
What Hash value has been provided: MD5 or SHA1. Depending on the eDiscovery platform, you may need to choose which internal field the hash value will need to be loaded to. (in Venio, we have the option of storing 2 hash values… a PRIMARY_HASH_VALUE, and a SECONDARY_HASH_VALUE. Which goes in which field is all controlled in the Project Settings).
Links / Paths to the Native, Image, or OCR File
Although most vendors and platforms ensure that the paths are correct, there are specific settings on export that may mean that a path has the full UNC File or a different referencing method to the file. If this is the case, you may need to REPLACE the path with the proper path to where the data is actually stored on your servers.
BATES NUMBER vs. Another CONTROL NUMBER
Most Vendors and ESI Protocols will use BATES Numbering. However, it is possible to use other system generated CONTROL NUMBERS as the primary unique record identifier. Make sure you understand which key fields should be used.
In closing, by no means is this list of tips, and things to watch for complete… rather it is a good starting point to help you review and better understand the data that may be exchanged and cause you to really think about how the other side may have to handle or address data when you are working through your ESI Protocol or at your Meet and Confer.
Would you like to learn more about our services? Email [email protected] or call 289-803-9730. We’d be happy to share more details about our self-service or fully managed eDiscovery services!





